A practical guide to vector databases: embeddings, HNSW vs IVF-PQ, hybrid search, tuning recall-latency, and FAISS code to ship production semantic search. Includes working examples and benchmarks.
Why your keyword search keeps missing obvious matches: A user searches for “laptop repair near me”—your system returns “computer fixing services nearby.” Perfect match semantically, but zero keyword overlap.
That’s the vector database advantage.
Vector databases power the “semantic” layer of modern AI systems. Instead of matching exact strings, they compare embeddings—high-dimensional vectors that capture meaning from text, images, audio, code, molecules, and more.
What you’ll learn: - 🎯 When you need a vector DB (and when you don’t)
1 What is a Vector Database?
A vector database stores and indexes embeddings—dense vectors (e.g., 384–4096 dimensions) produced by models such as: - Sentence transformers - CLIP (vision-language models) - Whisper (audio) - Multimodal foundation models - Domain-specific encoders
The core task is nearest neighbor search: given a query vector, return the most similar stored vectors under a metric (cosine, L2, inner product).
When You DON’T Need a Vector Database
For small datasets (< 10,000 documents): - Exact search or in-memory libraries may suffice - Elasticsearch/OpenSearch with vector fields work well - Use vector DBs when you have: millions+ vectors, strict latency SLAs (< 50ms P95), complex filtering, or high QPS (100s-1000s)
1.1 Why vectors?
Because similar concepts map to nearby points in embedding space. “puppy on grass” and “dog on lawn” sit close even if they share few keywords.
# Example: Creating simple embeddings to demonstrate vector similarityimport numpy as npfrom sklearn.metrics.pairwise import cosine_similarity# Simulated embeddings for demonstration (in reality, these come from models)embeddings = {"puppy on grass": np.array([0.8, 0.6, 0.3, 0.5]),"dog on lawn": np.array([0.75, 0.65, 0.35, 0.52]),"cat in house": np.array([0.3, 0.2, 0.9, 0.1]),"car on road": np.array([0.1, 0.15, 0.2, 0.95])}# Calculate similarity between "puppy on grass" and other phrasesquery = embeddings["puppy on grass"].reshape(1, -1)print("Similarity scores to 'puppy on grass':\n")for phrase, vec in embeddings.items():if phrase !="puppy on grass": similarity = cosine_similarity(query, vec.reshape(1, -1))[0][0]print(f"{phrase:20s}: {similarity:.4f}")
Similarity scores to 'puppy on grass':
dog on lawn : 0.9972
cat in house : 0.6027
car on road : 0.6168
2 End-to-End Flow
The vector database workflow consists of five key stages:
2.1 Vectorization
Unstructured data → embedding model → vector \(\mathbf{x} \in \mathbb{R}^d\).
Often you also normalize: \(\mathbf{x} \leftarrow \frac{\mathbf{x}}{\|\mathbf{x}\|}\) if using cosine similarity.
2.2 Storage & Metadata
Store {id, vector, metadata, payload}. Metadata enables filters (e.g., country=US, doc_type=blog) and post-retrieval ranking.
2.3 Indexing
Build an ANN (Approximate Nearest Neighbor) index so queries don’t scan every vector. Trade speed for a controlled loss vs exact search.
2.4 Query
Query text/image → query vector \(\mathbf{q}\). Perform ANN search with optional metadata filters and hybrid fusion (keyword + vector).
# Example: End-to-end vector database flow simulationimport numpy as npfrom sklearn.preprocessing import normalize# Step 1: Vectorization (simulated embeddings)documents = ["Machine learning with neural networks","Deep learning for computer vision","Natural language processing with transformers","Database systems and indexing","Vector search and embeddings"]# Simulate embedding generation (in practice, use real models like sentence-transformers)np.random.seed(42)dim =128doc_embeddings = np.random.randn(len(documents), dim).astype('float32')# Step 2: Normalize for cosine similaritydoc_embeddings = normalize(doc_embeddings, norm='l2', axis=1)# Step 3: Store with metadatametadata = [ {"doc_id": i, "category": "ML", "year": 2024} for i inrange(len(documents))]print(f"Stored {len(documents)} documents with {dim}-dimensional embeddings")print(f"Embedding shape: {doc_embeddings.shape}")print(f"Sample embedding (first 10 dims): {doc_embeddings[0][:10]}")
Properties: - Equivalent to cosine if vectors are normalized - If not normalized, may use transform tricks (e.g., add a norm-dependent extra dimension) to reuse L2 engines
Pro Tip: Cosine ≡ Dot Product (when normalized)
Quick proof: If vectors are L2-normalized (\(\|\mathbf{x}\| = \|\mathbf{y}\| = 1\)):
Practical benefit: Use faster inner-product indexes (FAISS IndexFlatIP) instead of cosine distance computation. Just normalize once at ingestion and query time.
Common Pitfall: Mixing Normalized & Unnormalized Vectors
Mixing normalized query vectors with unnormalized index vectors (or vice versa) breaks retrieval completely. Always verify:
# At index timevectors_normalized = vectors / np.linalg.norm(vectors, axis=1, keepdims=True)index.add(vectors_normalized)# At query timequery_normalized = query / np.linalg.norm(query)results = index.search(query_normalized, k=10)
💡 Tip: Decide metric before index build; many indexes are metric-specific and cannot be changed after training.
# Comparing different distance metricsimport numpy as npfrom sklearn.metrics.pairwise import cosine_similarity, euclidean_distancesimport matplotlib.pyplot as plt# Create two sample vectorsvec1 = np.array([[1.0, 2.0, 3.0]])vec2 = np.array([[2.0, 4.0, 6.0]]) # Same direction, different magnitudevec3 = np.array([[1.0, 2.0, -3.0]]) # Different direction# Normalize vectors for cosinevec1_norm = vec1 / np.linalg.norm(vec1)vec2_norm = vec2 / np.linalg.norm(vec2)vec3_norm = vec3 / np.linalg.norm(vec3)print("Distance Metrics Comparison:\n")print("="*60)# Cosine similaritycos_sim_12 = cosine_similarity(vec1, vec2)[0][0]cos_sim_13 = cosine_similarity(vec1, vec3)[0][0]print(f"Cosine Similarity:")print(f" vec1 vs vec2 (same direction): {cos_sim_12:.4f}")print(f" vec1 vs vec3 (diff direction): {cos_sim_13:.4f}")# Euclidean distancel2_dist_12 = euclidean_distances(vec1, vec2)[0][0]l2_dist_13 = euclidean_distances(vec1, vec3)[0][0]print(f"\nEuclidean Distance (L2):")print(f" vec1 vs vec2: {l2_dist_12:.4f}")print(f" vec1 vs vec3: {l2_dist_13:.4f}")# Inner productinner_12 = np.dot(vec1, vec2.T)[0][0]inner_13 = np.dot(vec1, vec3.T)[0][0]print(f"\nInner Product:")print(f" vec1 vs vec2: {inner_12:.4f}")print(f" vec1 vs vec3: {inner_13:.4f}")print("\n"+"="*60)print("\n💡 Notice: Cosine sees vec1 and vec2 as identical (both 1.0)")print(" because they point in the same direction, despite magnitude difference!")
Distance Metrics Comparison:
============================================================
Cosine Similarity:
vec1 vs vec2 (same direction): 1.0000
vec1 vs vec3 (diff direction): -0.2857
Euclidean Distance (L2):
vec1 vs vec2: 3.7417
vec1 vs vec3: 6.0000
Inner Product:
vec1 vs vec2: 28.0000
vec1 vs vec3: -4.0000
============================================================
💡 Notice: Cosine sees vec1 and vec2 as identical (both 1.0)
because they point in the same direction, despite magnitude difference!
4 Index Families (and When to Use Them)
Different indexing strategies optimize for various trade-offs between speed, accuracy, and memory.
4.1 Graph-based (HNSW - Hierarchical Navigable Small World)
Pros: - Excellent recall/speed trade-off - Dynamic insert capabilities - Strong default for ≤ few hundred million points in RAM
Cons: - Memory-heavy (stores graph structure) - Deletions are lazy or complicated - Filtering can be non-trivial
Pros: - Simple implementation - Memory-mapped for efficient disk usage - Good for read-mostly workloads
Cons: - Slower writes - Less optimal for dynamic updates
4.4 Specialized Indexes
• ScaNN: Anisotropic quantization for better compression (Google Research)
• DiskANN: I/O-aware for large-scale cloud disk storage (Microsoft Research)
• Flat/Brute-force: Exact search, costly but useful for small collections or re-ranking
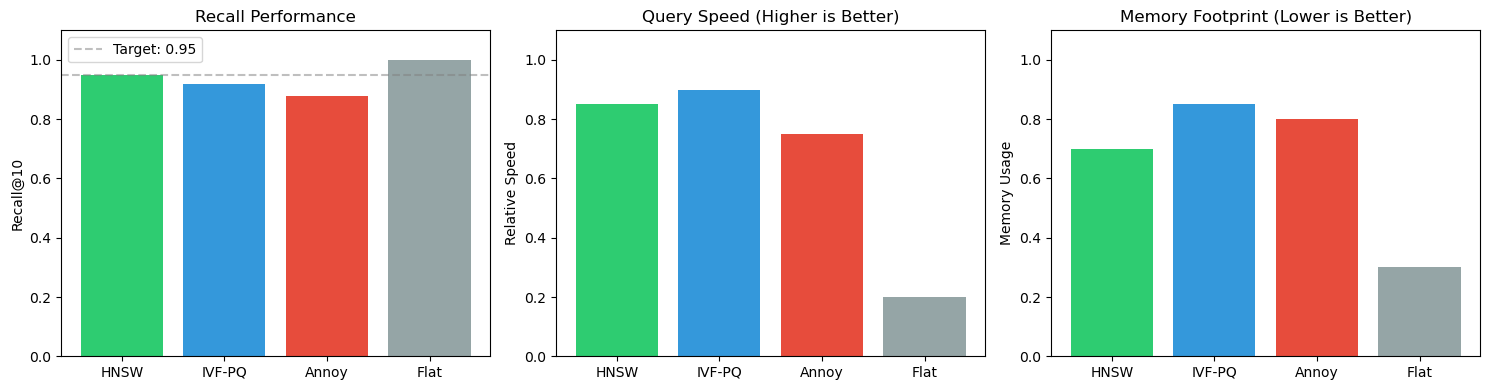
# Visualizing index performance characteristicsimport matplotlib.pyplot as pltimport numpy as np# NOTE: These are illustrative trade-offs, not measured benchmarks# For real numbers, benchmark with your data and workloadindex_types = ['Flat\n(Exact)', 'HNSW', 'IVF-PQ', 'Annoy']recall = [1.0, 0.95, 0.92, 0.88] # Illustrativespeed = [1, 50, 80, 40] # Relative QPSmemory = [100, 150, 30, 60] # Relative memory usagefig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(14, 4))# Recall comparisonax1.bar(index_types, recall, color='#3498db', alpha=0.8)ax1.set_ylabel('Recall@10', fontsize=11)ax1.set_title('Recall (Illustrative)', fontsize=12, fontweight='bold')ax1.set_ylim([0.8, 1.05])ax1.axhline(y=0.95, color='red', linestyle='--', alpha=0.5, label='Target: 0.95')ax1.legend()ax1.grid(True, alpha=0.3, axis='y')# Speed comparisonax2.bar(index_types, speed, color='#2ecc71', alpha=0.8)ax2.set_ylabel('Relative Speed (QPS)', fontsize=11)ax2.set_title('Search Speed (Illustrative)', fontsize=12, fontweight='bold')ax2.grid(True, alpha=0.3, axis='y')# Memory comparisonax3.bar(index_types, memory, color='#e74c3c', alpha=0.8)ax3.set_ylabel('Relative Memory', fontsize=11)ax3.set_title('Memory Usage (Illustrative)', fontsize=12, fontweight='bold')ax3.grid(True, alpha=0.3, axis='y')plt.tight_layout()plt.savefig('index_comparison.png', dpi=100, bbox_inches='tight')plt.show()print("\n⚠️ NOTE: These are illustrative trade-offs, not measured benchmarks")print("📊 Index Characteristics Summary:")print("="*60)for i, idx inenumerate(index_types):print(f"{idx:15s} | Recall: {recall[i]:.2f} | Speed: {speed[i]:3.0f}x | Memory: {memory[i]:3.0f}%")print("="*60)print("\n💡 Benchmark with YOUR data for real numbers!")
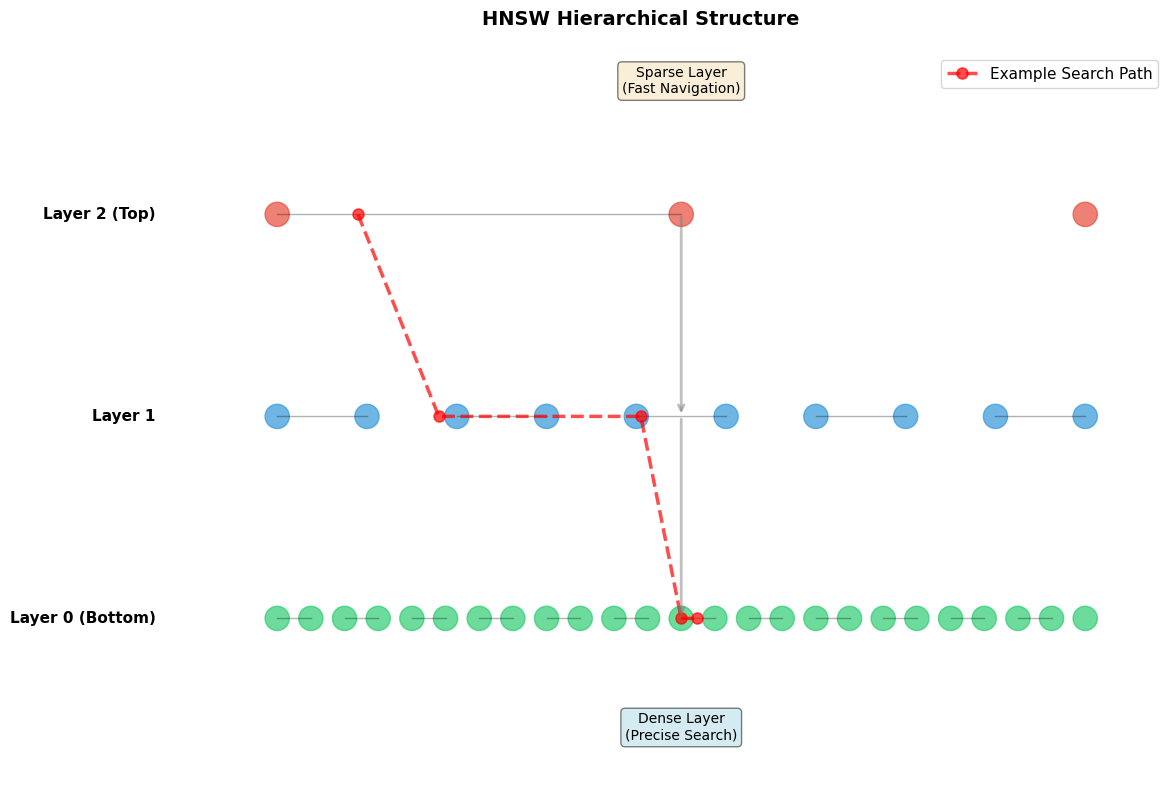
At the top layers, only a few nodes exist (sparse)
At the bottom layer, all nodes exist (dense)
Multiple layers create a hierarchical structure for fast navigation
5.2 Key Parameters
Parameter
Description
Impact
M
Max neighbors per node
Controls graph degree, recall, memory
efConstruction
Candidate list during build
Higher = better recall, slower build, more memory
efSearch
Candidate list during query
Higher = better recall, higher latency
5.3 Insertion Process
Assign layer: Random maximum layer to the new node (geometric distribution)
Start descent: Begin from entry point in the top layer
Greedy descent: At each layer, move to neighbors closer to the new vector
Link nodes: At target layer, link the node to its nearest neighbors using diversification heuristic (prune overly redundant edges)
Repeat down: Continue process down through all layers
5.4 Search Process
Start at top: Begin at the top entry point
Greedy search per layer: Move to the neighbor closest to query \(\mathbf{q}\) until no improvement
Descend: Move down one layer
Refine at bottom: At the bottom layer, perform best-first search with bounded candidate set size efSearch
Return top-k: Return the k nearest neighbors
5.5 Intuition
Upper layers “teleport” you near the right region (coarse navigation)
Bottom layer refines the search (fine-grained precision)
5.6 Trade-offs
Larger M, efConstruction, efSearch → higher recall & memory/latency
Complexity: Near log-like behavior empirically
Memory: \(\approx O(N \times M)\) edges + vectors
Memory Estimation for HNSW
For practical sizing, use this formula:
Memory ≈ N × (d × 4 bytes + M × 8 bytes)
Example: 100M vectors, d=768, M=16
= 100M × (768×4 + 16×8) bytes
= 100M × 3,200 bytes
= ~320 GB RAM
This is why HNSW works best for RAM-scale datasets (≤ few hundred million vectors).
# Visualizing HNSW layer structureimport matplotlib.pyplot as pltimport matplotlib.patches as mpatchesimport numpy as npfig, ax = plt.subplots(figsize=(12, 8))# Define layerslayers = [ {"name": "Layer 2 (Top)", "y": 7, "nodes": 3, "color": "#e74c3c"}, {"name": "Layer 1", "y": 4.5, "nodes": 10, "color": "#3498db"}, {"name": "Layer 0 (Bottom)", "y": 2, "nodes": 25, "color": "#2ecc71"}]# Draw layersfor layer in layers:# Draw nodes x_positions = np.linspace(1, 11, layer["nodes"]) y_pos = layer["y"]for x in x_positions: circle = plt.Circle((x, y_pos), 0.15, color=layer["color"], alpha=0.7) ax.add_patch(circle)# Draw some connections (simplified)if layer["nodes"] >1:for i inrange(len(x_positions) -1):if i %2==0and i +1<len(x_positions): ax.plot([x_positions[i], x_positions[i+1]], [y_pos, y_pos], 'k-', alpha=0.3, linewidth=1)# Label layer ax.text(-0.5, y_pos, layer["name"], fontsize=11, fontweight='bold', va='center', ha='right')# Draw vertical connections between layersax.annotate('', xy=(6, 4.5), xytext=(6, 7), arrowprops=dict(arrowstyle='->', color='gray', lw=2, alpha=0.5))ax.annotate('', xy=(6, 2), xytext=(6, 4.5), arrowprops=dict(arrowstyle='->', color='gray', lw=2, alpha=0.5))# Add annotationsax.text(6, 8.5, 'Sparse Layer\n(Fast Navigation)', ha='center', fontsize=10, bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))ax.text(6, 0.5, 'Dense Layer\n(Precise Search)', ha='center', fontsize=10, bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.5))# Add search path illustrationsearch_path_x = [2, 3, 5.5, 6, 6.2]search_path_y = [7, 4.5, 4.5, 2, 2]ax.plot(search_path_x, search_path_y, 'r--', linewidth=2.5, alpha=0.7, marker='o', markersize=8, label='Example Search Path')ax.set_xlim(-1, 12)ax.set_ylim(0, 9)ax.set_aspect('equal')ax.axis('off')ax.legend(loc='upper right', fontsize=11)ax.set_title('HNSW Hierarchical Structure', fontsize=14, fontweight='bold', pad=20)plt.tight_layout()plt.savefig('hnsw_structure.png', dpi=100, bbox_inches='tight')plt.show()print("\n🏗️ HNSW Structure Explained:")print("="*60)print("• Top layers: Few nodes, long-distance hops (coarse search)")print("• Bottom layer: All nodes, short hops (fine-grained search)")print("• Search starts at top and descends layer by layer")print("• Each layer acts as a 'highway' to quickly reach the target region")print("="*60)
🏗️ HNSW Structure Explained:
============================================================
• Top layers: Few nodes, long-distance hops (coarse search)
• Bottom layer: All nodes, short hops (fine-grained search)
• Search starts at top and descends layer by layer
• Each layer acts as a 'highway' to quickly reach the target region
============================================================
6 Beyond RAG: What Else Uses Vector Databases?
Vector databases power far more than just Retrieval-Augmented Generation. Here are key application areas:
6.1 Recommendation & Personalization
Retrieve similar users/items, complementing traditional collaborative filtering approaches.
6.2 Near-Duplicate & Plagiarism Detection
Deduplicate large corpora (news articles, code repositories, scientific preprints).
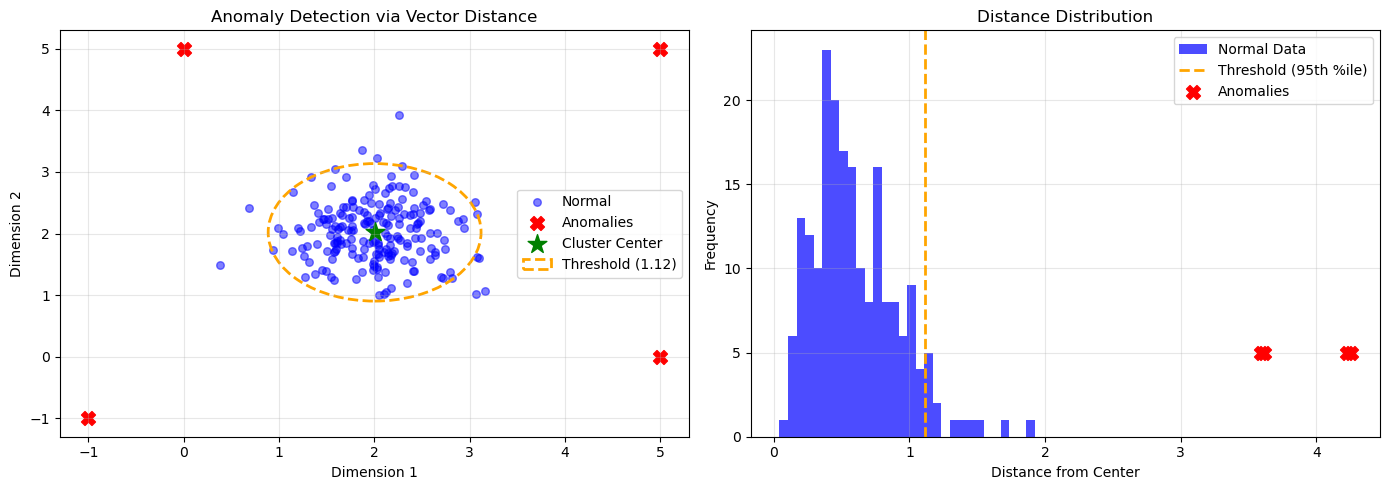
6.3 Anomaly/Outlier Detection
“Distance from manifold” heuristics for fraud detection, abuse prevention, or quality control.
6.4 Semantic Monitoring & Alerting
Watch streams (logs, support tickets) for semantically similar incidents to trigger alerts.
6.5 Multimodal Search
Image ↔︎ Text (CLIP-based)
Audio snippet search
Video moment retrieval
6.6 Code Intelligence
Similar function lookup
Cross-repository code search
Code clone detection
6.7 Bio/Chem Applications
Protein/compound embeddings for virtual screening
Scaffold hopping in drug discovery
Molecular similarity search
6.8 Robotics/SLAM & Mapping
Place recognition via local feature embeddings for autonomous navigation.
6.9 Legal & E-discovery
Concept clustering and semantic curation of legal documents.
6.10 Content Moderation
Identify similar policy-violating content across platforms.
Problem: Searching across multiple tenants/languages with post-filtering loses recall.
Solution: Pre-partition by high-selectivity filters.
# Comparison: Naive post-filter vs segment-by-filter# Scenario: Multi-tenant vector search with 3 tenantsprint("🔍 Filter Strategy Comparison\n")print("="*70)# Naive approach: Single global index + post-filterprint("\n❌ NAIVE: Global index + post-filter")print("-"*70)print("1. Search global index for k=10")print("2. Filter results by tenant_id='tenant_A'")print("3. Problem: May get 0-3 results (poor recall!)")print(" Example: If only 3/10 results match filter → 70% recall loss")print("\n✅ BETTER: Segment by tenant")print("-"*70)print("1. Maintain separate index per tenant:")print(" - index_tenant_A (10M vectors)")print(" - index_tenant_B (15M vectors)") print(" - index_tenant_C (8M vectors)")print("2. Route query to correct tenant index")print("3. Search returns full k=10 results")print("4. Benefit: 100% recall, faster (smaller index per search)")# Code patternprint("\n💻 Implementation Pattern:")print("-"*70)code ='''# Segment-by-filter patterntenant_indexes = { 'tenant_A': faiss.IndexIVFPQ(...), 'tenant_B': faiss.IndexIVFPQ(...), 'tenant_C': faiss.IndexIVFPQ(...)}def search_with_filter(query_vec, tenant_id, k=10): # Route to correct index - no post-filtering needed index = tenant_indexes[tenant_id] distances, indices = index.search(query_vec, k) return indices# vs naive post-filter (loses recall)def naive_search(query_vec, tenant_id, k=10): # Search global index with larger k to compensate distances, indices = global_index.search(query_vec, k*5) # Need 5x! # Post-filter (slow + unpredictable recall) filtered = [i for i in indices if metadata[i]['tenant'] == tenant_id] return filtered[:k]'''print(code)print("\n⚡ Rule of thumb:")print(" • <10 filter values (tenant, lang) → Segment indexes")print(" • Range filters (date) → Post-filter with larger k")print(" • High cardinality (user_id) → Use hybrid DB (Qdrant, Weaviate)")print("="*70)
8 Data & Model Concerns
Getting embeddings right is crucial for vector database performance.
Critical: Be consistent across index & query - Cosine similarity requires normalized vectors - MIPS equivalence depends on normalization - Mixing normalized and unnormalized vectors breaks retrieval
8.3 Drift & Versioning
Challenge: New models produce incompatible embeddings
Solutions: - Keep vector schema version metadata - Maintain multiple indexes during transition - Re-index incrementally (dual-write pattern) - A/B test new embeddings before full rollout
8.4 Chunking for Text
Key considerations: - Window size: 256–1024 tokens common - Stride/Overlap: 20–30% overlap prevents information loss at boundaries - Chunk re-assembly: Maintain document relationships - Context preservation: Include surrounding context in metadata
# Example: Text chunking strategiesdef chunk_text_with_overlap(text, chunk_size=100, overlap=20):""" Split text into overlapping chunks. Args: text: Input text string chunk_size: Size of each chunk in characters overlap: Overlap between consecutive chunks Returns: List of text chunks """ chunks = [] start =0while start <len(text): end = start + chunk_size chunk = text[start:end] chunks.append({'chunk_id': len(chunks),'text': chunk,'start_pos': start,'end_pos': min(end, len(text)),'length': len(chunk) }) start += (chunk_size - overlap)return chunks# Example textsample_text ="""Vector databases are specialized systems designed to store and query high-dimensional vectors efficiently. These vectors, or embeddings, are dense numerical representations of data such as text, images, or audio. The key advantage of vector databases is their ability to perform semantic search, finding similar items based on meaning rather than exact keyword matches. This makes them essential for modern AI applications including recommendation systems, similarity search, and retrieval-augmented generation (RAG) systems."""# Create chunks with different strategieschunks_no_overlap = chunk_text_with_overlap(sample_text, chunk_size=100, overlap=0)chunks_with_overlap = chunk_text_with_overlap(sample_text, chunk_size=100, overlap=20)print("\n📄 Text Chunking Strategies\n")print("="*70)print(f"\nOriginal text length: {len(sample_text)} characters\n")print("Strategy 1: No Overlap")print(f" → {len(chunks_no_overlap)} chunks created")for i, chunk inenumerate(chunks_no_overlap[:3], 1):print(f"\nChunk {i} (chars {chunk['start_pos']}-{chunk['end_pos']}):")print(f" {chunk['text'][:50]}...")print("\n"+"-"*70)print("\n\nStrategy 2: With 20% Overlap")print(f" → {len(chunks_with_overlap)} chunks created")for i, chunk inenumerate(chunks_with_overlap[:3], 1):print(f"\nChunk {i} (chars {chunk['start_pos']}-{chunk['end_pos']}):")print(f" {chunk['text'][:50]}...")print("\n"+"="*70)print("\n💡 Benefits of overlap:")print(" • Prevents information loss at chunk boundaries")print(" • Maintains context across chunks")print(" • Improves retrieval recall for cross-boundary concepts")
📄 Text Chunking Strategies
======================================================================
Original text length: 531 characters
Strategy 1: No Overlap
→ 6 chunks created
Chunk 1 (chars 0-100):
Vector databases are specialized systems designed ...
Chunk 2 (chars 100-200):
iently. These vectors, or embeddings, are dense nu...
Chunk 3 (chars 200-300):
ges, or audio. The key advantage of vector
databa...
----------------------------------------------------------------------
Strategy 2: With 20% Overlap
→ 7 chunks created
Chunk 1 (chars 0-100):
Vector databases are specialized systems designed ...
Chunk 2 (chars 80-180):
sional vectors efficiently. These vectors, or embe...
Chunk 3 (chars 160-260):
epresentations of data such as text, images, or au...
======================================================================
💡 Benefits of overlap:
• Prevents information loss at chunk boundaries
• Maintains context across chunks
• Improves retrieval recall for cross-boundary concepts
9 Evaluation: Quantify “Good”
Measuring vector database performance requires multiple metrics across different dimensions.
9.1 Retrieval Quality Metrics
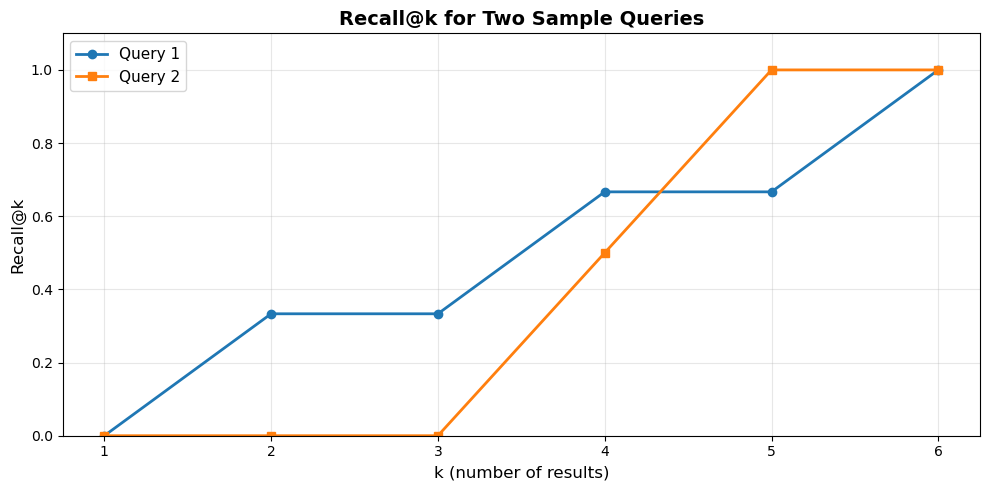
9.1.1 Recall@k
\[\text{Recall@k} = \frac{\text{# relevant items in top-k}}{\text{total # relevant items}}\]
Measures what fraction of relevant items are retrieved in top-k results. Compare against exact search or high-ef baseline.
Production vector databases require careful operational planning.
10.1 Index Build & Updates
Batch Operations: - Offline batch build for major changes - Schedule during low-traffic periods - Use distributed build for large datasets
Streaming Updates: - Real-time upserts for freshness requirements - Balance throughput vs consistency - Monitor lag between write and searchability
Delete Handling: - Lazy deletes with tombstone markers - Background consolidation/compaction - Plan for periodic full rebuilds
Deployment Strategy: - Keep read replicas for zero-downtime updates - Blue/green deployment for index version changes - Gradual rollout with traffic splitting
10.2 Sharding Strategies
Hash Sharding: - Uniform distribution by document ID - Simple routing logic - Good for load balancing
High recall, low business metrics (CTR/conversion)
Chunking too large or wrong granularity
Test 256 vs 512 vs 1024 token chunks
Pick size that maximizes downstream metric
Recall degrades over time
Model drift or data distribution shift
Compare current vs baseline recall@k weekly
Re-index with updated embeddings; A/B test new model
Fast offline, slow in production
Cold cache or network latency
Profile with/without warm cache
Add query result caching; pre-warm frequently-accessed vectors
Good vector scores, irrelevant results
Embedding model not domain-specific
Test domain-specific vs generic embeddings
Fine-tune or switch to domain-adapted model (SciBERT, CodeBERT, etc.)
High memory usage
Large M/efConstruction or no quantization
Measure memory per million vectors
Use PQ compression; reduce M; consider IVF-PQ instead of HNSW
Filters return too few results
Post-filtering after low-k ANN search
Increase k before filtering (e.g., 100→500)
Pre-partition index by common filters or increase candidate k
Inconsistent recall across queries
Some queries OOD (out-of-distribution)
Cluster queries, measure recall per cluster
Identify weak clusters; add training data; use query reformulation
12 Practical Sizing & Tuning Cheatsheet
A quick reference guide for getting started with vector database configuration.
12.1 🎯 Production Defaults: Start Here
Copy-paste these settings for a working baseline:
Scenario
Index
Starting Configuration
Small scale (≤50M vectors, RAM)
HNSW
M=16, efConstruction=200, efSearch=64
Large scale (50M-1B, GPU)
IVF-PQ
nlist=√N, nprobe=16, m=64, nbits=8
Metric
Most text/NLP tasks
Cosine (normalize vectors!)
Target SLA
Production search
recall@10 ≥ 0.95, P95 latency ≤ 50ms
Quick sanity check: After indexing, run 100 test queries. If recall@10 < 0.90, increase efSearch or nprobe by 2x and remeasure.
12.2 Initial Setup Checklist
✅ Pick metric early (cosine vs L2 vs MIPS) - Cosine: Most common for text/semantic search - L2: When magnitude matters - MIPS: For asymmetric similarity tasks
✅ Choose index based on scale:
≤ 50M vectors, RAM-based:
# HNSW configurationindex = HNSWIndex( dim=768, M=16, # Start with 16-32 efConstruction=200, # 200-400 for good recall efSearch=64, # Tune based on latency SLO metric='cosine')
50M–1B vectors or GPU:
# IVF-PQ configurationnlist =int(np.sqrt(n_vectors)) # e.g., 31,623 for 1B vectorsindex = IVFPQIndex( dim=768, nlist=nlist, nprobe=16, # Start with 8-64 m=64, # PQ subvectors nbits=8, # bits per subvector metric='cosine')
12.3 Tuning for Latency SLO
Target: 95% recall@k with P95 latency < threshold
Baseline: Start with conservative params
Measure: Run benchmark queries, measure recall & latency
Iterate: Gradually increase efSearch/nprobe
Monitor: Stop when latency SLO is met or recall plateaus
# Example tuning loopparams = [32, 64, 128, 256, 512]for ef in params: index.efSearch = ef recall, p95_latency = benchmark(index, test_queries)print(f"ef={ef}: recall={recall:.3f}, P95={p95_latency:.1f}ms")if recall >=0.95and p95_latency <= target_latency:break
12.4 Hybrid Search Setup
# Enable both vector and keyword searchconfig = {'vector_search': {'enabled': True,'weight': 0.7 },'keyword_search': {'enabled': True,'algorithm': 'BM25','weight': 0.3 },'fusion_method': 'RRF', # or 'weighted_sum''reranker': {'model': 'cross-encoder/ms-marco-MiniLM-L-6-v2','top_k': 100# Re-rank top 100 from fusion }}
12.5 Filter Configuration
# Segment by common filtersfilter_strategy = {'tenant_id': 'pre_partition', # High cardinality'language': 'segment_index', # Low cardinality (10-20 values)'publish_date': 'post_filter', # Range filter'category': 'segment_index'# Common query pattern}
Let’s build a complete working example using FAISS, one of the most popular vector search libraries.
13.1 Installation
# CPU versionpip install faiss-cpu# GPU version (if CUDA is available)pip install faiss-gpu
13.2 Complete IVF-PQ Implementation
Below is a production-style implementation using FAISS with IVF-PQ indexing.
# Complete FAISS example with IVF-PQ indexing# Note: Install faiss-cpu first: pip install faiss-cpu numpyimport numpy as npimport time# For visualizationimport matplotlib.pyplot as pltprint("="*70)print("Vector Database with FAISS: Complete Example")print("="*70)# ============================================================================# Step 1: Generate synthetic embeddings# ============================================================================print("\n📊 Step 1: Generating synthetic embeddings...")np.random.seed(42)d =768# embedding dimension (typical for sentence transformers)nb =100000# number of vectors in the databasenq =100# number of queries# Create synthetic embeddings (in practice, use real embedding models)xb = np.random.randn(nb, d).astype('float32')xq = np.random.randn(nq, d).astype('float32')# Normalize for cosine similarity (important!)xb = xb / np.linalg.norm(xb, axis=1, keepdims=True)xq = xq / np.linalg.norm(xq, axis=1, keepdims=True)print(f" ✓ Created {nb:,} database vectors")print(f" ✓ Created {nq:,} query vectors")print(f" ✓ Dimension: {d}")print(f" ✓ Memory footprint: {xb.nbytes /1024**2:.2f} MB")# ============================================================================# Step 2: Build the index# ============================================================================print("\n🏗️ Step 2: Building IVF-PQ index...")try:import faiss# IVF-PQ parameters nlist =256# number of clusters (cells) m =64# number of subquantizers (must divide d evenly) nbits =8# bits per subquantizer# Create quantizer (for coarse search) quantizer = faiss.IndexFlatIP(d) # Inner Product = cosine for normalized vectors# Create IVF-PQ index index = faiss.IndexIVFPQ(quantizer, d, nlist, m, nbits)# Train the index (k-means + PQ training)print(f" • Training index with nlist={nlist}, m={m}, nbits={nbits}...") start = time.time() index.train(xb) train_time = time.time() - startprint(f" ✓ Training completed in {train_time:.2f} seconds")# Add vectors to the indexprint(f" • Adding {nb:,} vectors...") start = time.time() index.add(xb) add_time = time.time() - startprint(f" ✓ Vectors added in {add_time:.2f} seconds")print(f" ✓ Index contains {index.ntotal:,} vectors")# ============================================================================# Step 3: Search# ============================================================================print("\n🔍 Step 3: Performing search...")# Set search parameters index.nprobe =16# number of clusters to search (recall/latency trade-off) k =10# return top-10 neighborsprint(f" • Search parameters: nprobe={index.nprobe}, k={k}")# Perform search start = time.time() scores, indices = index.search(xq, k) search_time = time.time() - startprint(f" ✓ Searched {nq} queries in {search_time*1000:.2f} ms")print(f" ✓ Throughput: {nq/search_time:.0f} QPS")print(f" ✓ Average latency: {search_time/nq*1000:.2f} ms per query")# ============================================================================# Step 4: Display results# ============================================================================print("\n📋 Step 4: Sample results...")print("\nFirst query results:")print(f" Top-{k} neighbor IDs: {indices[0]}")print(f" Top-{k} scores: {scores[0].round(4)}")# ============================================================================# Step 5: Tune nprobe for recall/latency trade-off# ============================================================================print("\n⚙️ Step 5: Tuning nprobe parameter...") nprobe_values = [1, 2, 4, 8, 16, 32, 64] latencies = []for nprobe in nprobe_values: index.nprobe = nprobe start = time.time() _, _ = index.search(xq[:10], k) # Test with 10 queries elapsed = (time.time() - start) /10*1000# ms per query latencies.append(elapsed)# Plot results fig, ax = plt.subplots(figsize=(10, 5)) ax.plot(nprobe_values, latencies, marker='o', linewidth=2, markersize=8) ax.set_xlabel('nprobe (number of clusters searched)', fontsize=12) ax.set_ylabel('Latency (ms per query)', fontsize=12) ax.set_title('Search Latency vs nprobe', fontsize=14, fontweight='bold') ax.grid(True, alpha=0.3) ax.set_xscale('log', base=2)# Annotate pointsfor i, (np_val, lat) inenumerate(zip(nprobe_values, latencies)): ax.annotate(f'{lat:.2f}ms', xy=(np_val, lat), xytext=(5, 5), textcoords='offset points', fontsize=9) plt.tight_layout() plt.savefig('faiss_nprobe_tuning.png', dpi=100, bbox_inches='tight') plt.show()print("\n"+"="*70)print("✅ FAISS example completed successfully!")print("="*70)exceptImportError:print("\n⚠️ FAISS not installed. Install with: pip install faiss-cpu")print("\nHere's what the code would do:")print(" 1. Create an IVF-PQ index with cosine similarity")print(" 2. Train the index on 100K vectors")print(" 3. Perform fast approximate nearest neighbor search")print(" 4. Demonstrate recall/latency trade-offs")exceptExceptionas e:print(f"\n❌ Error: {e}")print("This example requires FAISS. Install with: pip install faiss-cpu")
======================================================================
Vector Database with FAISS: Complete Example
======================================================================
📊 Step 1: Generating synthetic embeddings...
✓ Created 100,000 database vectors
✓ Created 100 query vectors
✓ Dimension: 768
✓ Memory footprint: 292.97 MB
🏗️ Step 2: Building IVF-PQ index...
• Training index with nlist=256, m=64, nbits=8...
✓ Created 100,000 database vectors
✓ Created 100 query vectors
✓ Dimension: 768
✓ Memory footprint: 292.97 MB
🏗️ Step 2: Building IVF-PQ index...
• Training index with nlist=256, m=64, nbits=8...
✓ Training completed in 74.89 seconds
• Adding 100,000 vectors...
✓ Training completed in 74.89 seconds
• Adding 100,000 vectors...
✓ Vectors added in 2.02 seconds
✓ Index contains 100,000 vectors
🔍 Step 3: Performing search...
• Search parameters: nprobe=16, k=10
✓ Searched 100 queries in 30.00 ms
✓ Throughput: 3334 QPS
✓ Average latency: 0.30 ms per query
📋 Step 4: Sample results...
First query results:
Top-10 neighbor IDs: [37887 91949 41194 83788 94566 41790 6916 51013 37990 63991]
Top-10 scores: [1.347 1.3475 1.3595 1.3597 1.3658 1.3721 1.3754 1.3778 1.3783 1.3784]
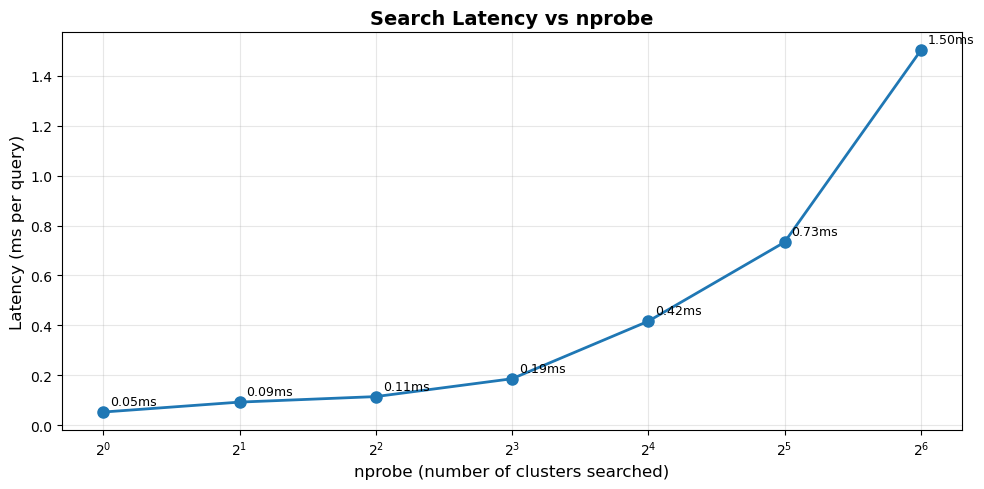
⚙️ Step 5: Tuning nprobe parameter...
✓ Vectors added in 2.02 seconds
✓ Index contains 100,000 vectors
🔍 Step 3: Performing search...
• Search parameters: nprobe=16, k=10
✓ Searched 100 queries in 30.00 ms
✓ Throughput: 3334 QPS
✓ Average latency: 0.30 ms per query
📋 Step 4: Sample results...
First query results:
Top-10 neighbor IDs: [37887 91949 41194 83788 94566 41790 6916 51013 37990 63991]
Top-10 scores: [1.347 1.3475 1.3595 1.3597 1.3658 1.3721 1.3754 1.3778 1.3783 1.3784]
⚙️ Step 5: Tuning nprobe parameter...
======================================================================
✅ FAISS example completed successfully!
======================================================================
13.3 Notes on Production Usage
Metadata Filtering: FAISS doesn’t natively support metadata filters. Common approaches: - Use an external database (PostgreSQL, Redis) for metadata - Filter results after retrieval (post-filtering) - Use wrapper libraries like LanceDB or Qdrant that support filters
Hybrid Search: Combine FAISS with traditional search engines:
# Save indexfaiss.write_index(index, "vector_index.faiss")# Load indexindex = faiss.read_index("vector_index.faiss")
Cross-Encoder Re-ranking:
from sentence_transformers import CrossEncoder# Get candidates from FAISScandidates = index.search(query_vec, k=100)# Re-rank with cross-encoderreranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')scores = reranker.predict([(query_text, doc_text) for doc_text in candidate_docs])final_results = sort_by_scores(candidates, scores)[:10]
14 Frequently Asked Questions (FAQ)
14.1 Q1: Do I always need a vector database?
A: Not for small corpora. For datasets with < 10,000 documents: - Exact search or in-memory libraries may suffice - Search libraries with vector support (Elasticsearch/OpenSearch) work well - Scale, latency requirements, filter complexity, and operational needs drive the decision
When you DO need a dedicated vector DB: - Millions+ of vectors - Strict latency requirements (< 50ms P95) - Complex metadata filtering - High QPS (hundreds to thousands) - Need for advanced features (hybrid search, re-ranking, analytics)
14.2 Q2: Cosine vs Inner Product vs L2 — which should I use?
A: It depends on your embedding model and task:
Cosine Similarity: - Best for: Text embeddings, semantic search - Requires: Normalized vectors - Properties: Magnitude-invariant, captures direction
Inner Product (MIPS): - Best for: When you normalize vectors (equivalent to cosine) - Use case: Asymmetric similarity tasks - Note: Faster than cosine if vectors are pre-normalized
L2 Distance: - Best for: When magnitude carries meaning - Use case: Some vision tasks, specific embedding schemes - Properties: Sensitive to scale
Rule of thumb: For most NLP/text applications, use cosine (with normalization).
14.3 Q3: Can I mix different embedding models in one index?
A: Generally avoid mixing incompatible embedding spaces:
Problem: - Different models create incompatible vector spaces - Distances become meaningless across model boundaries
Solutions: 1. Separate indexes per model: Shard by model_version, merge results in application 2. Re-embed everything: When upgrading models, re-process entire corpus 3. Dual-write pattern: Maintain both versions during transition
A: Common practice: 256–1024 tokens with 20–30% overlap
Considerations:
Chunk Size
Pros
Cons
Small (128-256)
Precise matches, less noise
May lack context
Medium (512)
Good balance
Standard choice
Large (1024+)
Rich context
May be too general
Best practice: - Experiment with your specific use case - Measure retrieval quality (recall, NDCG) - Consider downstream task (Q&A needs precision, summarization needs context) - Use overlap to prevent information loss at boundaries
14.5 Q5: What about GPU vs CPU for vector search?
A: Choose based on workload characteristics:
GPU Advantages: - Massive parallelism for batch queries - Excellent for IVF-PQ indexes - Great for re-ranking large candidate sets - Cost-effective at very high QPS
CPU Advantages: - HNSW performs well on CPU - Lower latency for single queries - Easier deployment and scaling - More flexible for diverse workloads
Hybrid Approach: - Use CPU for HNSW-based serving - GPU for batch re-embedding and index building - GPU for re-ranking top-k candidates
14.6 Q6: How do I handle real-time updates?
A: Multiple strategies depending on freshness requirements:
Streaming Upserts:
# Real-time updates with eventual consistencyindex.upsert(doc_id, embedding, metadata)# Visible within seconds to minutes
# For major rebuilds1. Build new_index offline2. Warm up new_index (cache, test queries)3. Switch traffic: old_index → new_index4. Deprecate old_index
14.7 Q7: What’s the best open-source vector database?
A: Depends on your requirements:
Database
Best For
Key Strengths
FAISS
Research, prototyping
Performance, flexibility, GPU support
Milvus
Production scale
Distributed, cloud-native, rich features
Qdrant
Moderate scale
Easy API, good filtering, Rust performance
Weaviate
Hybrid search
GraphQL, modules, good docs
Chroma
RAG applications
Simple API, embeddings built-in
Pinecone
Managed service
Serverless, zero-ops, good DX
14.8 Q8: How do I debug poor recall?
Checklist:
✅ Check embeddings: Are they normalized consistently?
✅ Verify metric: Cosine vs L2 vs inner product
✅ Tune parameters: Increase efSearch/nprobe
✅ Test with exact search: Compare ANN vs brute force
✅ Inspect queries: Are they in-distribution?
✅ Check filters: Post-filtering too aggressive?
✅ Evaluate embedding model: Is it appropriate for your domain?
✅ Look for drift: Has data distribution changed?
Diagnostic code:
# Compare ANN vs exact searchexact_neighbors = exact_index.search(query, k=10)ann_neighbors = ann_index.search(query, k=10)recall =len(set(exact_neighbors) &set(ann_neighbors)) /10print(f"Recall@10: {recall}")
15 TL;DR - Key Takeaways
15.1 🎯 Core Concepts
✅ Vector databases enable semantic search by storing and querying high-dimensional embeddings
✅ ANN (Approximate Nearest Neighbor) indexes trade a small accuracy loss for massive speed gains
✅ Distance metrics matter: Cosine for text (normalized), L2 when magnitude matters, MIPS for specialized tasks
15.2 🏗️ Index Selection
Scale
Recommendation
Key Parameters
≤ 50M
HNSW
M=16-32, efConstruction=200-400, efSearch=64-200
50M-1B
IVF-PQ
nlist=√N, nprobe=8-64, PQ 8-16 bits
Web-scale
DiskANN or sharded IVF-PQ
+ tiered storage, caching
15.3 ⚙️ Production Essentials
Hybrid search: Combine vector + keyword (BM25) with RRF fusion
Metadata filters: Pre-partition by common filters or post-filter with larger k
Re-ranking: Use cross-encoders on top-100 for precision
Monitoring: Track recall@k, latency (P50/P95), QPS, and business metrics
Versioning: Dual-write during model transitions, blue-green deployment
15.4 🔍 Evaluation Framework
# Essential metrics- Recall@k (≥ 0.95 target)- NDCG@k (for ranking quality)- P95 latency (<50ms typical)- Cost per million vectors- User engagement (CTR, task success)
15.5 🚀 Getting Started
Step 1: Choose your metric (cosine for most text tasks)
Step 2: Start simple: - Small scale: HNSW with default params - Large scale: IVF-PQ on GPU
Step 3: Measure baseline (recall, latency, cost)
Step 4: Iterate: - Tune efSearch/nprobe for recall/latency balance - Add hybrid search if keywords matter - Implement re-ranking for precision
Step 5: Operationalize: - Monitor key metrics - Set up alerts for recall degradation - Plan for model version migrations - Implement caching and sharding strategies
15.6 💡 Common Pitfalls to Avoid
❌ Mixing normalized and unnormalized vectors
❌ Ignoring metadata filters in initial design
❌ Not measuring recall against exact search baseline
❌ Underestimating memory requirements
❌ Forgetting about the cold start problem
❌ No plan for embedding model versioning
❌ Optimizing for accuracy without considering latency